
Comprendre facilement le Machine Learning grâce au Titanic et sans code⚓🧠🤖
TL;DR
Découvrez les principes clés du machine learning supervisé et créez pas à pas votre première IA sans rien installer, ni écrire une seule ligne de code. Facile !
Le challenge ? Prédire qui a survécu au naufrage du Titanic
Disclaimer
Cet article sera relativement long.
Je vous encourage à utiliser le sommaire ci-dessus pour accéder directement aux parties qui vous intéressent. En particulier, cliquez-ici pour sauter la théorie et aller directement à l’étude de cas.
État d’esprit
J’aime à lire comme une poule boit, en relevant fréquemment la tête, pour faire couler.
Jules Renard
Je vous invite à lire cet article par petit morceaux, en y revenant.
La première partie qui présente les concepts mérite que l’on prenne le temps de les comprendre. La seconde qui parcoure leur mise en oeuvre et d’autant plus intéressante si vous prenez le temps de jouer avec l’outil.

C’est parti !
Tout le monde connait l’histoire du RMS Titanic et le destin tragique plus de 2/3 de ses passagers en 1912. Ils ont inspiré James Cameron en 1997 pour un film bien connu. Ils ont aussi inspiré la plateforme Kaggle en 2011 pour une compétition de Data Science toujours ouverte.
Les participants y construisent des modèles de machine learning pour prédire quels passagers ont survécu.
Machine Learning 101
Ce sujet est idéal pour expérimenter et comprendre les principes fondamentaux du machine learning. Plus précisément, c’est le moyen de mettre les mains dans l’apprentissage supervisé.
Les outils cloud actuels tels permettent de jouer le cas d’application sans écrire une seule ligne de code.
Cet article est l’occasion d’aborder des concepts comme
- L’apprentissage supervisé
- La validation croisée (cross validation)
- La précision
- La sensibilité (recall)
Pour la mise en œuvre, j’utiliserai Azure ML Studio.
Note 1 :
Des alternatives sont possibles : Google Cloud AI Platform, Amazon SageMaker, IBM Watson Studio, DataRobot, H2O.ai, Dataiku.
Note 2 :
D’autres concepts comme le sur-apprentissage (overfitting) ou le sur-échantillonnage (over sampling) pourront être abordés et illustrés dans un autre article.
Les étapes d’un projet de Data Science

De manière générale, un projet de Data Science passe toujours par les mêmes étapes :
01. Définition du problème : déterminer le but du projet et ce que l’on souhaite accomplir en utilisant les données.
02. Collecte de données : réunir toutes les données pertinentes pour le projet, que ce soit en les recueillant soi-même (dans son SI), en les achetant, ou en les récupérant à l’extérieur (sur internet par exemple)
03. Nettoyage de données : préparer les données pour l’analyse en les organisant, en les normalisant et en les nettoyant afin d’éliminer toutes les données manquantes ou incorrectes.
04. Exploration de données : analyser les données pour en comprendre les tendances et les patterns, en utilisant des techniques de visualisation de données et de statistiques. On parle d’EDA : Exploratory Data Analysis.
05. Modélisation : construire un modèle de prédiction en utilisant les données préparées et explorées précédemment.
06. Évaluation : mesurer l’efficacité du modèle en utilisant des métriques appropriées et en comparant les résultats obtenus avec ceux attendus.
07. Optimisation : (si nécessaire) mettre à jour le modèle en apportant des modifications afin de l’améliorer.
08. Déploiement : mettre en œuvre le modèle dans un environnement de production, en le rendant disponible pour les utilisateurs ou en l’intégrant à une application existante.
Note 1 :
Il est important de noter que ces étapes ne sont pas nécessairement linéaires et qu’il peut y avoir des retours en arrière à certaines étapes.
Par exemple, le nettoyage de données peut être effectué à plusieurs reprises au cours du projet, et l’exploration de données peut être nécessaire pour aider à la définition du problème ou à l’optimisation du modèle.
Note 2 :
Par soucis de simplification, je n’aborde pas ici les dimensions de communication, d’accompagnement du changement ou encore juridique qui font partie des projets Data (Science).
Note 3 :
Les étapes d’optimisation et de déploiement ne seront pas traité dans l’étude de cas de cet article
Quelques concepts à connaitre avant de plonger dans le cas
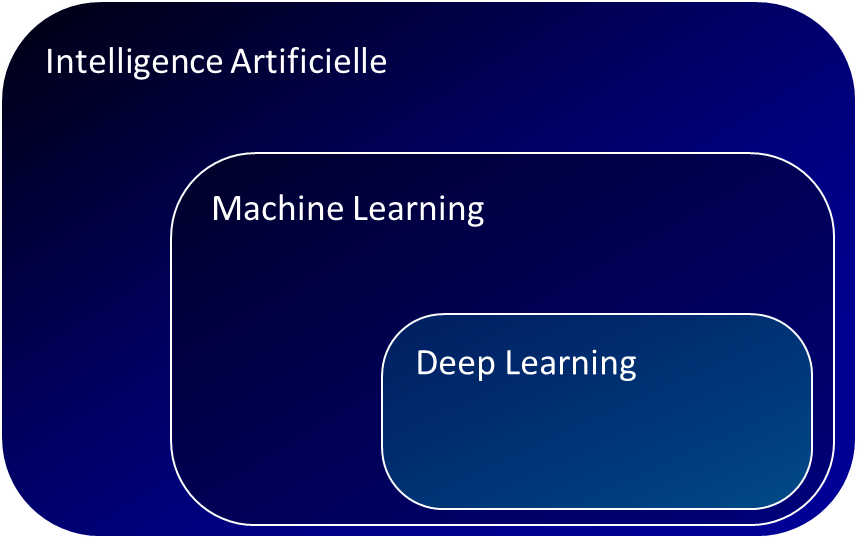
Intelligence Artificielle (IA) et Machine Learning (ML)
Les systèmes experts
Le concept d’IA remonte aux années 1950. Dans ses premières années, il s’agissait principalement d’être capable de reproduire les mécanismes intellectuels d’un expert. Pour cela, les projets consistaient à faire réaliser une base de règles fixes par un expert métier (matrice) puis à utiliser un moteur de règles afin d’appliquer cette base de règles.
Le Machine Learning (apprentissage automatique)
Le machine learning, qui fait partie de l’IA, consiste à utiliser des algorithmes pour permettre à un ordinateur d'”apprendre” à partir de données sans avoir été explicitement programmé pour effectuer une tâche particulière. La discipline a connu un véritable essor dans les années 1990 grâce aux avancées technologiques et à l’augmentation de la puissance de calcul des ordinateurs.
Le Deep Learning
Le deep learning est un sous-domaine de l’apprentissage automatique qui utilise des réseaux de neurones profonds (deep neural networks) pour apprendre à partir de données. Contrairement aux algorithmes de machine learning traditionnels, qui nécessitent souvent une préparation et une structure des données, les réseaux de neurones profonds peuvent apprendre directement à partir de données brutes, telles que des images, du texte ou des enregistrements audio. Le deep learning a été particulièrement efficace pour résoudre des tâches complexes comme la reconnaissance de l’objet et de la parole, et a connu un fort développement depuis le milieu des années 2000.
Type d’apprentissage au sein du Machine Learning
Apprentissage supervisé
Principe
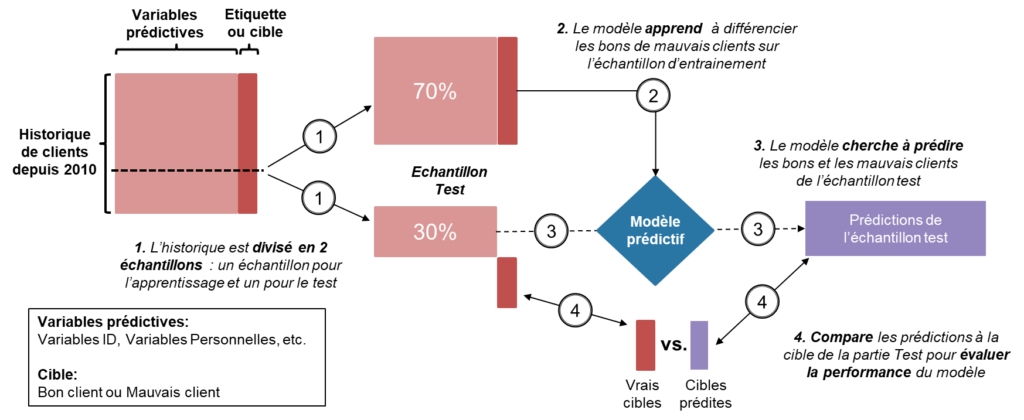
L’apprentissage supervisé est une technique de machine learning dans laquelle un modèle est entraîné à effectuer une tâche précise en utilisant des données d’entraînement étiquetées. Ces données d’entraînement comprennent des exemples de ce que le modèle doit apprendre à faire, ainsi que les “étiquettes” correctes associées à chaque exemple.
Exemples
Par exemple, pour entraîner un modèle à reconnaître les chats dans des images, nous pourrions utiliser des données d’entraînement comprenant des milliers d’images étiquetées comme “chat” ou “pas chat”. Le modèle utilisera ces données d’entraînement pour apprendre à reconnaître les caractéristiques courantes des chats (telle que la forme de la tête, la queue, etc.) et à prédire si une image donnée contient un chat ou non.
Dans un contexte professionnel, un autre exemple peut être de prédire si un client sera ou non fidèle et rentable (un “bon” client).
Une fois entraîné, le modèle peut être utilisé pour faire des prédictions sur de nouvelles données (que l’on appelle souvent données de test). Si le modèle a été correctement entraîné, il devrait être capable de faire de bonnes prédictions sur les données de test étiquetées de la même manière que les données d’entraînement.
De manière non exhaustive, cette technique comprend les activités de
- Classification
- Régression
- Classement (ranking)
- Prédiction
Récapitulatif visuel
Apprentissage non supervisé
Principe
L’apprentissage non supervisé est une autre technique de machine learning dans laquelle un modèle est entraîné à découvrir des patterns ou des structures dans des données sans utiliser de données étiquetées. Cela signifie que le modèle n’est pas fourni avec des exemples de ce qu’il doit apprendre à faire et qu’il doit trouver lui-même les structures dans les données.
Exemples
Imaginons que nous avons un sac rempli de billes de différentes couleurs et que nous souhaitons les regrouper en fonction de leurs similitudes. Pour ce faire, nous pouvons utiliser un algorithme de clustering (un type d’apprentissage non supervisé) pour regrouper les billes en groupes similaires. Par exemple, nous pourrions obtenir des groupes de billes rouges, de billes jaunes, de billes vertes, etc. Le tout sans avoir appris (apprentissage supervisé) à la machine, par exemple, ce qu’est une bille rouge.
Dans un contexte professionnel, un exemple peut être de détecter des transactions qui diffèrent des autres (suspectes).
De manière non exhaustive, cette technique comprend les activités de
- Clustering (regroupement)
- Réduction de dimension
- Reconnaissance de modèle
- Détection d’anomalie
Apprentissage par renforcement
Principe
L’apprentissage par renforcement est une troisième technique de machine learning. Dans celle-ci un agent interagit avec son environnement en prenant des actions. Il reçoit des récompenses ou des punitions en fonction des résultats de ses actions. L’objectif de l’agent est d’apprendre à maximiser sa récompense à long terme en ajustant ses actions en fonction de ses expériences passées.
Exemples
Imaginons que nous avons un robot qui doit apprendre à naviguer dans un labyrinthe. À chaque fois que le robot prend une décision (par exemple, tourner à droite ou à gauche), il reçoit une récompense ou une punition en fonction de s’il s’approche ou s’éloigne de la sortie du labyrinthe. L’apprentissage par renforcement consiste à faire en sorte que le robot apprenne à prendre les décisions qui lui permettront d’obtenir la plus grande récompense à long terme, en ajustant ses actions en fonction de ses expériences passées.
Dans un cadre professionnel, ce peut être un moteur de recommandation basé sur l’apprentissage par renforcement. Alors l’agent est l’utilisateur et l’environnement est le système de recommandation. L’agent interagit avec l’environnement en cliquant sur des recommandations. Il reçoit alors des récompenses sous la forme de temps passé sur le contenu recommandé. L’objectif de l’agent est d’apprendre à maximiser sa récompense en cliquant sur des recommandations qui lui plaisent vraiment.
Validation croisée
Principe
La validation croisée est une technique utilisée pour évaluer la performance d’un modèle de machine learning sur des données de test.
Elle consiste à
- Diviser l’ensemble de données en plusieurs parties appelées “plis” (folds)
- A entraîner le modèle sur une partie des données (appelée “ensemble d’entraînement” (train set))
- À le tester sur l’autre partie (appelée “ensemble de validation” (validation set)).
Cette procédure est répétée plusieurs fois en utilisant différents plis de données à chaque fois. Cela permet d’obtenir une estimation plus précise de la performance du modèle.
Utilité
La validation croisée permet de mesurer la performance du modèle sur des données qui n’ont pas été utilisées pour l’entraîner. C’est important pour évaluer sa capacité à généraliser à de nouvelles données. Elle est également utile pour sélectionner les meilleurs hyperparamètres pour un modèle. C’est-à-dire les paramètres qui déterminent le comportement de l’algorithme de machine learning. Enfin, elle permet de limiter le sur-entrainement du modèle.
Note : Ces notions d’hyperparamètres et de sur-entrainement ne seront pas développées ici.
Illustration visuelle
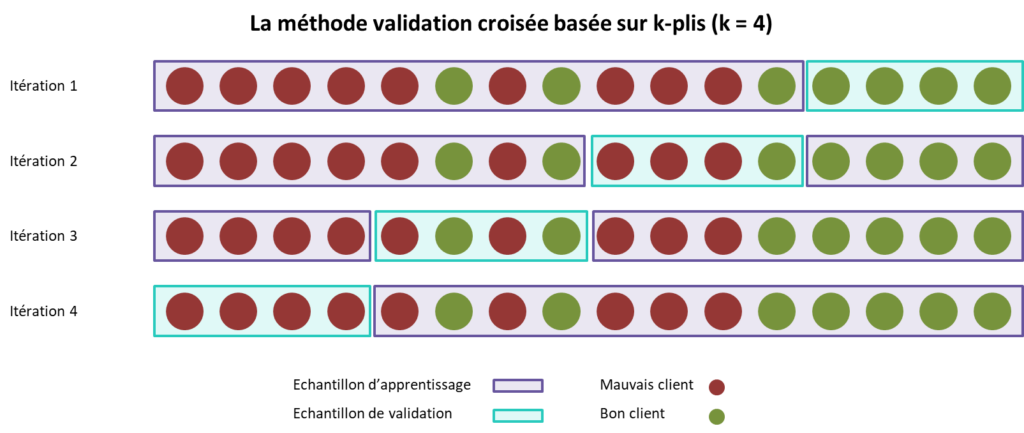
Le visuel ci-dessus illustre l’importance d’entrainer et de tester un modèle selon plusieurs découpages du jeu de donnée. En effet, l’exemple de la première itération montre que le modèle pourrait apprendre “exagérément” la présence de mauvais clients. De plus, il pourrait présenter de mauvaises performances, car testé sur un groupe comportant exclusivement des mauvais clients.
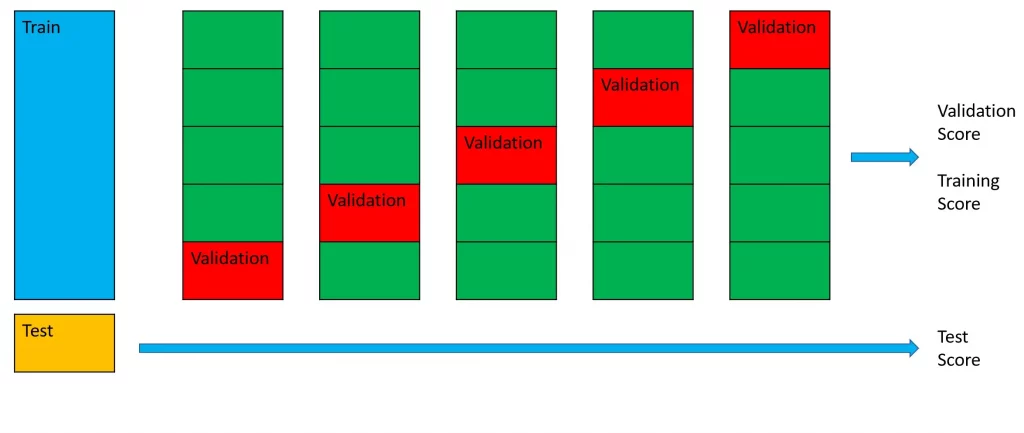
Note :
Pour simplifier le propos, je ne rentre volontairement pas dans la distinction entre jeux d’entrainement, de validation et de test. L’article Medium de Valentina Alto dont est tiré le visuel ci-contre donne plus d’informations.
En synthèse, c’est bien le jeu d’entraînement qui est subdivisé pour créer celui de validation.
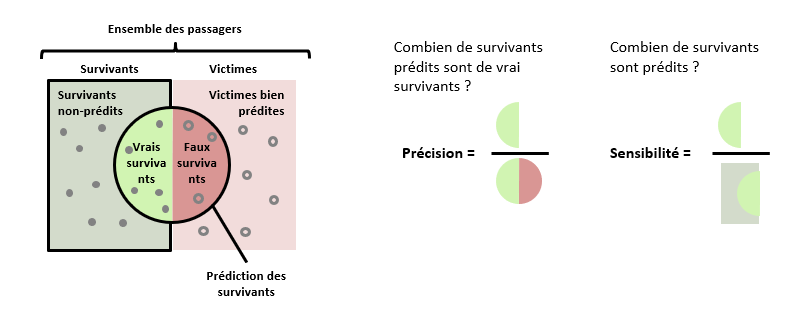
Précision et sensibilité
La précision est la proportion de prédictions correctes.
Dans le cadre de notre exemple, la précision du modèle sera sa capacité à avoir raison lorsqu’il prédit qu’un passager va survivre. Elle peut être calculée ainsi : Sur 100 passagers prédits comme survivants, combien ont réellement survécu ?
La sensibilité mesure la capacité d’un modèle à identifier ce que l’on cherche à prédire.
Dans le cadre de notre exemple, la sensibilité du modèle sera sa capacité à identifier les personnes qui ont survécu. Elle peut être calculée ainsi : sur 100 survivants, combien ont effectivement été prédits comme tels par le modèle ?
La performance du modèle sera évaluée, entre autres, selon ces deux mesures. Le challenge vient de fait que l’amélioration de l’une se fait souvent aux dépens de l’autre.
Par exemple, prenons un modèle qui prédirait la survie de tous les passagers. Sa sensibilité serait parfaite, mais sa précision serait mauvaise. À l’inverse, s’il prédit un seul survivant et qu’il a raison, alors il a une précision parfaite, mais une mauvaise sensibilité
Vrais/Faux Positifs/Négatifs
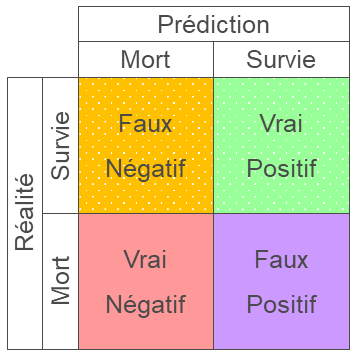
La comparaison entre la réalité et la prédiction du modèle permet de distinguer les 4 catégories ci-dessus.
Ainsi la précision est égale à :
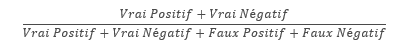
Taux de Vrai Positif (True Positive Rate)
Ratio entre les prédictions justes de survie et l’ensemble des passagers qui survivent en réalité
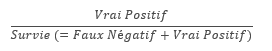
Taux de Faux Positif (False Positive Rate)
Ratio entre les prédictions erronées de survie et l’ensemble des passagers morts en réalité
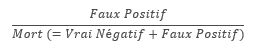
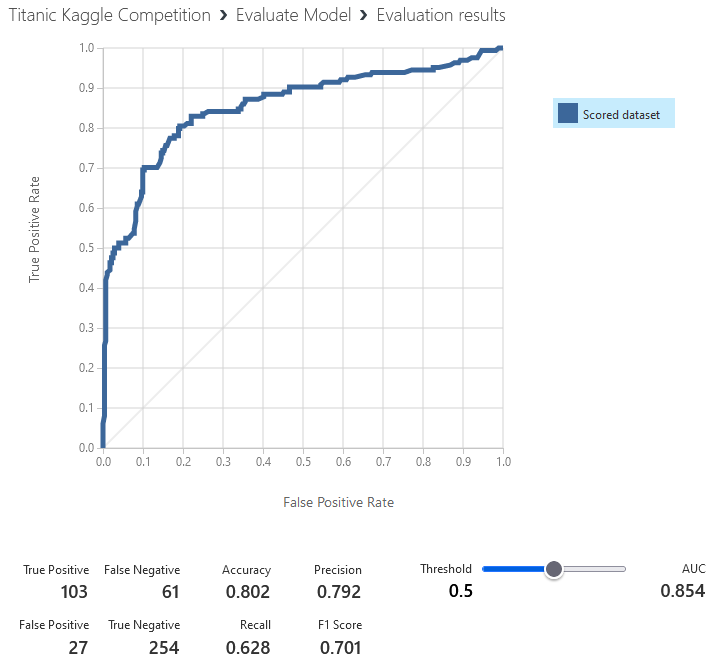
Courbe ROC
La courbe ROC présente le taux de faux positif en fonction de celui de vrai positif. Elle permet de fixer le seuil optimal à utiliser pour séparer les prédictions de survie de celles de décès.
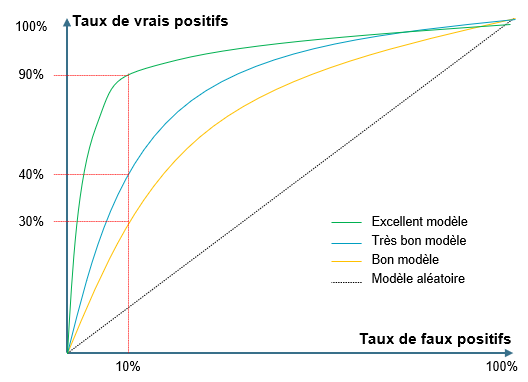
> Sur l’illustration, en acceptant un taux de faux positifs de 10% les différents modèles permettent de prédire jusqu’à 90% des survivants.
>Pour chaque modèle, en définissant le taux de faux positifs acceptable on fixe aussi le taux de vrais positifs atteignable et le niveau seuil à sélectionner pour séparer les survivants des autres.
Utilisation de Microsoft Machine Learning Studio
Pour utiliser Machine Learning Studio, vous n’avez pas forcément besoin d’un compte Microsoft :
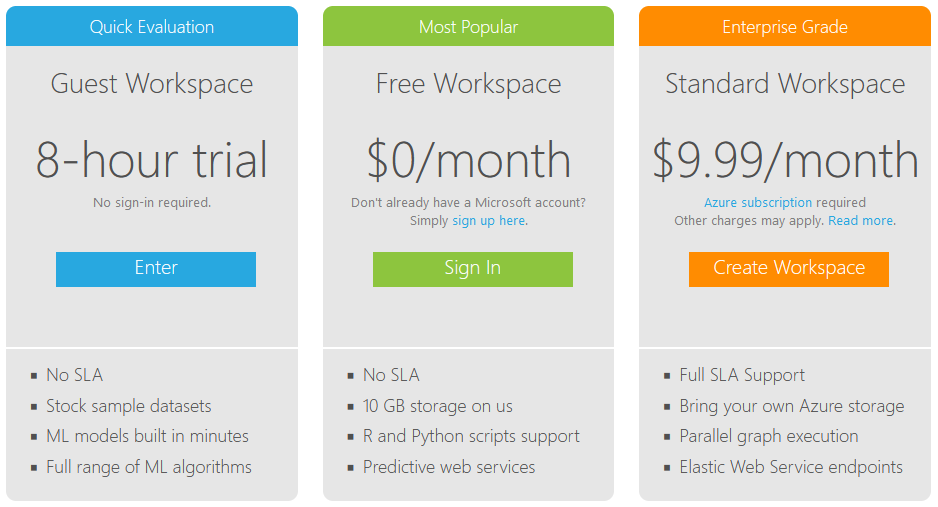
Comme l’indique le visuel ci-dessus, il est possible d’utiliser l’outil gratuitement pendant 8 heures (renouvelables indéfiniment). Je recommande cependant d’utiliser un compte Microsoft pour accéder à l’offre gratuite qui permettra d’avoir un espace de travail pérenne.
Voici le lien pour vous connecter : https://studio.azureml.net/
Une fois connectés, fermer la fenêtre qui s’ouvre (cliquez sur “close”) :

Vous devriez alors avoir une interface qui ressemble à celle-ci :
Le lien suivant vous permet d’importer le modèle pré-construit pour cette compétition Kaggle : ici
Validez la région en cliquant sur la coche en bas à droite :
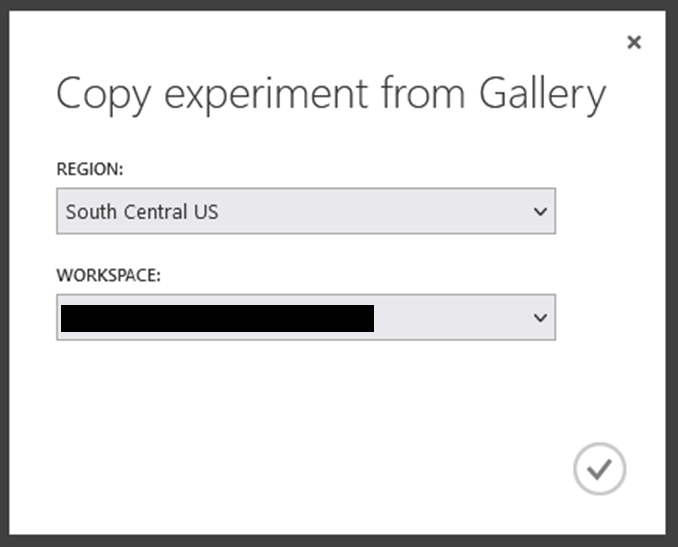
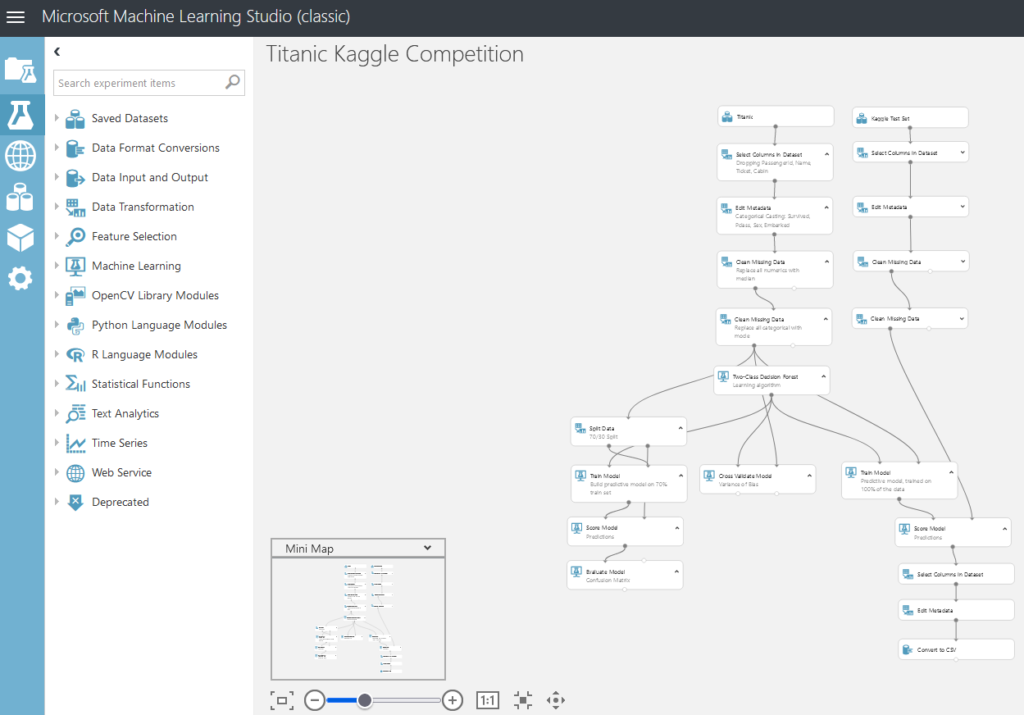
Et vous voici presque prêts avec un écran qui devrait ressembler à celui-ci :
Il ne vous reste plus qu’à cliquer sur “Run” en bas de votre écran et à patienter (~1’20”).
Revenons-en au Titanic
Définition du problème
Déterminer le but du projet et ce que l’on souhaite accomplir en utilisant les données.
C’est assez simple : nous souhaitons entrainer un modèle de machine learning qui sera capable de prédire si un passager du Titanic a survécu ou non au naufrage.
Collecte de données
Réunir toutes les données pertinentes pour le projet, que ce soit en les recueillant soi-même (dans son SI), en les achetant, ou en les récupérant à l’extérieur (sur internet par exemple)
Fichiers
Les données sont disponibles sur la page Kaggle dédiée ainsi qu’en téléchargement direct ci-dessous. J’ajoute un document Excel contenant le fichier d’entrainement (train) et quelques tableaux croisés basiques.
Attention : vous n’avez pas besoin de ces fichiers si vous avez utilisé l’import de modèle préconstruit sur Machine Learning Studio (voir plus haut)
Variables
Les variables présentes sont les suivantes :
- PassengerId : le numéro unique du passager dans le cadre de ce jeu de donnée
- Survived : un booléen indiquant si le passager a survécu (1) ou non (0)
- Pclass : la classe de voyage du passager (1, 2 ou 3)
- Name : le nom du passager
- Sex : le sexe du passager (homme ou femme)
- Age : l’âge du passager en années
- SibSp : le nombre de frères et sœurs/conjoints à bord du navire
- Parch : le nombre de parents/enfants à bord du navire
- Ticket : le numéro de ticket du passager
- Fare : le prix du billet du passager
- Cabin : le numéro de cabine du passager
- Embarked : le port d’embarquement du passager (C = Cherbourg, Q = Queenstown, S = Southampton)
Deux types de variables
Il faut distinguer la variable que l’on va chercher à prédire (la variable dépendante) de celles qui vont nous servir à construire cette prédiction (les autres variables, appelées features).
Dans notre cas, la variable dépendante est donc “Survived” et les autres sont les features que l’on va utiliser pour entrainer le modèle.
Nettoyage de données
Préparer les données pour l’analyse en les organisant, en les normalisant et en les nettoyant afin d’éliminer toutes les données manquantes ou incorrectes.
Préambule :
- Dans le cadre de cet exercice “pédagogique” nous allons nettoyer rapidement, voir grossièrement, les données. Il sera possible d’y revenir plus finement par la suite pour améliorer les performances du modèle
- J’illustrerai avec Azure ML Studio, mais les opérations décrites ci-dessous peuvent être réalisées avec l’outil de votre choix, à commencer par Excel.
Suppression des variables inutiles
Pour une première approche, nous pouvons considérer les variables ci-dessous comme inutiles. J’entends par là qu’il est très peu probable qu’elles soient porteuses d’informations cruciales pour prédire la survie du passager concerné ou bien qu’elles sont significativement corrélées avec une autre variable.
Je vous invite à relire la liste des variables et à vous faire votre propre avis avant d’afficher la liste ci-dessous
- PassengerId : le numéro unique du passager dans le cadre de ce jeu de donnée
- Name : le nom du passager
- Ticket : le numéro de ticket du passager
- Cabin : le numéro de cabine du passager
Si vous avez choisi de travailler avec Excel, vous pouvez donc supprimer les colonnes en question.
Si vous utilisez le modèle ML Studio, il s’agit de la première étape réalisée après avoir importé le jeu de données d’entrainement :

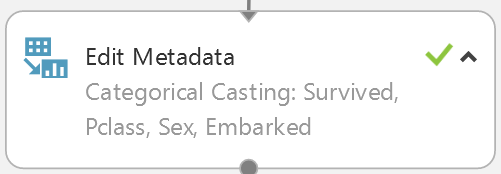
Catégorisation des variables
Il est nécessaire de préciser que plusieurs variables doivent être traitées comme des catégories. En particulier la variable “Survived”. Comme elle ne contient que des 0 et des 1, elle sera par défaut traitée comme une variable numérique. Ainsi les variables “Survived”, “Pclass”, “Sex”, et “Embarked” doivent être considérée comme des catégories.
C’est ce que fait l’étape suivante :
Nettoyage des données manquantes
Si l’on regarde les données restantes après cette étape :
On s’aperçoit que pour l’age, il y en a beaucoup. 177 pour être exact :

Nous allons remplacer ces valeurs manquantes par la médiane : 28 ans (cf. l’image précédente).
C’est ce que fait le bloc suivant :

Nous allons faire la même chose pour les données manquantes non numériques en les remplaçant par leur mode, c’est-à-dire la valeur qu’elles prennent le plus souvent.
C’est le cas de la variable “Embarked” où il manque 2 fois la donnée.
Ce vide sera comblé par la valeur S :
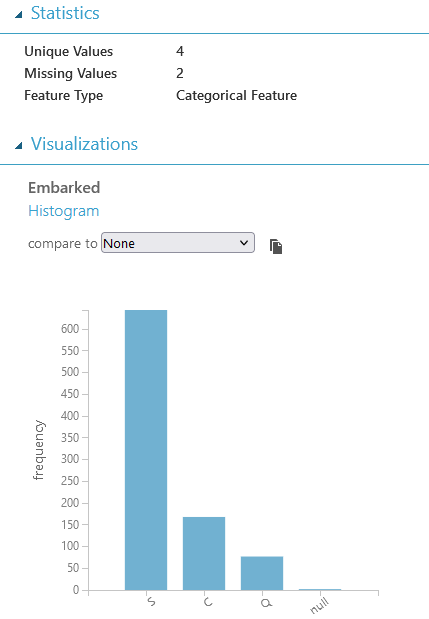
C’est ce que fait le bloc suivant :

À ce stade, nous pouvons considérer que nous avons un jeu de données propre, prêt pour l’étape suivante.
Exploration des données
Analyser les données pour en comprendre les tendances et les patterns, en utilisant des techniques de visualisation de données et de statistiques. On parle d’EDA : Exploratory Data Analysis.
Le moment est venu d’analyser et d’explorer vos données. Cela va vous permettre de mieux les comprendre, de formuler des hypothèses et de mener des analyses spécifiques pour les confirmer ou les infirmer.
C’est aussi lors de cette étape que vous allez pouvoir créer de nouvelles variables sur la base de celles déjà présentes. On parle de feature engineering.
C’est ici un mélange de statistiques et de connaissances sur le fond du sujet que vous cherchez à traiter.
D’un point de vue statistique
Plusieurs mesures sont disponibles, sans être exhaustif : moyenne, médiane, mode, variance, covariance, coefficient d’acuité (kurtosis), coefficient d’asymétrie (skewness). La représentation graphique peut aussi être très utile.
Ces analyses permettent de se faire une idée des données et des éléments qui pourraient servir la prédiction.
Je laisse par exemple les visuels suivant à votre interprétation :
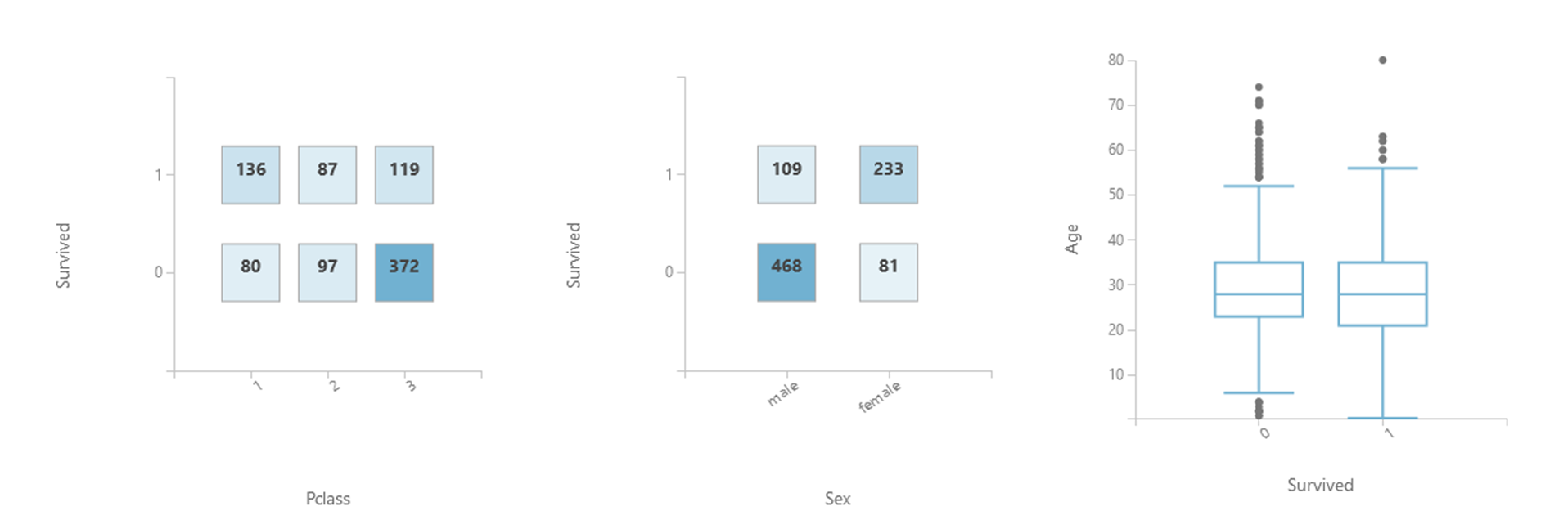
La connaissance du fond du sujet
“Les femmes et les enfants d’abord !”
Dans notre cas, il est utile de connaitre les pratiques de l’époque en cas de naufrage.
Il serait aussi utile de connaitre les plans du Titanic et plus précisément l’emplacement des escaliers ou échelles de secours. Le cas échéant, peut-être que l’information du numéro de cabine n’aurait pas dû être écartée.
De même pour le nom : peut-être que certains pouvaient rendre la survie plus probable ?
Quoi qu’il en soit, cet article ne couvrira pas le feature engineering.
Pour autant, n’hésitez pas à explorer comment vous pourriez enrichir le jeu de donnée initial.
Modélisation
Construire un modèle de prédiction en utilisant les données préparées et explorées précédemment.
Commençons par séparer le jeu de données obtenu en deux : l’un d’entrainement et l’autre de validation.
C’est ce que fait ce bloc :
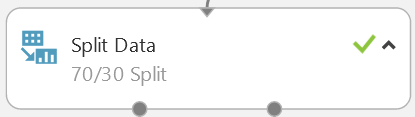
Notez que la répartition peut être choisie et que le modèle pré-construit chargé comporte une erreur : sa description indique 70/30 alors que le paramètre est à 50% :

Nous allons ensuite entrainer un modèles sur la base de la partie d’entrainement des données :

Dans cet exemple nous allons utiliser une forêt aléatoire :
Évaluation
Mesurer l’efficacité du modèle en utilisant des métriques appropriées et en comparant les résultats obtenus avec ceux attendus.
Le moment est venu de juger de l’efficacité de notre modèle. Pour se donner un point de comparaison, rappelons nous que 38% des personnes du jeu de données survivent. Aussi un modèle qui prédirait le decès de tous serait correct 62% du temps. Il faudra donc faire mieux que 62%. Les réponses exactes ont fuité, le leaderboard présente donc des scores de 100%. On peut cependant considérer que s’approcher des 90% est un très bon résultat.
Azure propose nativement les blocs nécessaires pour appliquer le modèle précédemment entrainé (c’est à dire formuler une prédiction) et évaluer sa performance :
En visualisant les résultats du bloc d’évaluation :
Nous pouvons alors voir que le modèle obtient une précision de 80% :
Validation croisée
Note : La notion de cross-validation est expliquée plus haut dans cet article.
La question se pose alors de savoir si cette performance est un coup de chance lié à la manière dont nous avons séparé en deux le jeu de données.
Ici encore l’outil propose le bloc dédié clé en main :

Par défaut le jeu de données est divisé en 10 plis (folds).
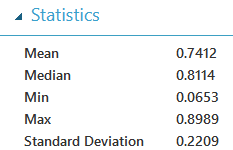
En regardant les résultats, on voit que les 80% obtenus plutôt sont un score supérieur à la moyenne (74%) et que le modèle est relativement instable avec écart-type élevé (0,22). En effet, l’intervalle de confiance à 95% de la précision est alors [0,58 ; 0,90]
Cela revient à dire qu’une boulangerie fait une baguette qui vaut en moyenne 7/10 mais dont chaque baguette à 95% de chance de valoir en 6/10 et 9/10.
Optimisation
Mettre à jour le modèle en apportant des modifications afin de l’améliorer.
ℹ️ Cette partie n’est pas traitée dans cet article.
Concernant l’exemple du Titanic déroulé ici, plusieurs pistes sont possibles :
- Construire de meilleures features comme par exemple, le fait d’être l’enfant ou le parent d’une famille, le fait de porter un titre particulier dans son nom ou encore d’avoir une cabine avec un emplacement particulier sur le bateau
- Mieux estimer/remplacer les valeurs manquantes, en particulier par l’age. Par exemple avec un modèle dédié
- Changer les hyperparamètres du modèles
- Changer de modèle
Il est important de noter que l’optimisation du modèle peut porter sur d’autres éléments que sa performance, comme par exemple son explicabilité, sa maintenabilité, ou encore sa rapidité.
Déploiement
Mettre en œuvre le modèle dans un environnement de production, en le rendant disponible pour les utilisateurs ou en l’intégrant à une application existante.
ℹ️ Cette partie n’est pas traitée dans cet article.
Sources, inspirations et liens utiles (en anglais)
- La page de la compétition sur Kaggle
. - Un guide pour créer vous-même le workflow sur ML Studio
- Notebooks Python de résolution sur Kaggle
- L’accès à Microsoft Azure Machine Learning Studio
- La page de la compétition Kaggle sur la plateforme Azure AI
- Le lien pour lancer le modèle de résolution directement dans Azure
. - Vidéo de résolution sur DataScienceDojo




{kind=link}
{kind=link}
{kind=link}